
DOM(文档对象模型)
温馨提示:这篇文章已超过541天没有更新,请注意相关的内容是否还可用!
DOM
文档对象模型
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口。根据W3C DOM规范,DOM是一种与浏览器,平台,语言的接口,使得你可以访问页面其他的标准组件。Document Object Model的历史可以追溯至1990年代后期微软与Netscape的“浏览器大战”,双方为在JavaScript与JScript一决生死,于是大规模的赋予浏览器强大的功能。微软在网页技术上加入了不少专属事物,计有VBScript、ActiveX、以及微软自家的DHTML格式等,使不少网页使用非微软平台及浏览器无法正常显示。DOM即是当时蕴酿出来的杰作。
| 中文名 | 文档对象模型 |
| 英文名 | Document Object Model |
| 简称 | DOM |
| 应用 | 处理可扩展标志语言 |
| 平台 | Windows |
背景介绍
DOM(Document Object Model),文档对象模型,DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构。换句话说,这是表示和处理一个HTML或XML文档的常用方法。有一点很重要,DOM的设计是以对象管理组织(OMG)的规约为基础的,因此可以用于任何编程语言。最初人们把它认为是一种让JavaScript在浏览器间可移植的方法,不过DOM的应用已经远远超出这个范围。Dom技术使得用户页面可以动态地变化,如可以动态地显示或隐藏一个元素,改变它们的属性,增加一个元素等,Dom技术使得页面的交互性大大地增强。
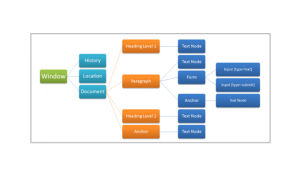
DOM实际上是以面向对象方式描述的文档模型。DOM定义了表示和修改文档所需的对象、这些对象的行为和属性以及这些对象之间的关系。可以把DOM认为是页面上数据和结构的一个树形表示,不过页面当然可能并不是以这种树的方式具体实现。
通过JavaScript,您可以重构整个HTML文档。您可以添加、移除、改变或重排页面上的项目。
要改变页面的某个东西,JavaScript就需要获得对HTML文档中所有元素进行访问的入口。这个入口,连同对HTML元素进行添加、移动、改变或移除的方法和属性,都是通过文档对象模型来获得的(DOM)。
在1998年,W3C发布了第一级的DOM规范。这个规范允许访问和操作HTML页面中的每一个单独的元素。
所有的浏览器都执行了这个标准,因此,DOM的兼容性问题也几乎难觅踪影了。
DOM可被JavaScript用来读取、改变HTML、XHTML以及XML文档。
DOM被分为不同的部分(核心、XML及HTML)和级别(DOM Level1/2/3):
DOM
DOM是W3C(万维网联盟)的标准。
DOM定义了访问HTML 和XML文档的标准:
W3C文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。"
W3C DOM 标准被分为3个不同的部分:
核心DOM-针对任何结构化文档的标准模型
XML DOM-针对XML文档的标准模型
HTML DOM-针对HTML文档的标准模型
XMLDOM
XML DOM是:
用于XML的标准对象模型
用于XML的标准编程接口
中立于平台和语言
W3C标准
XML DOM定义了所有XML元素的对象和属性,以及访问它们的方法(接口)。
换句话说:XML DOM是用于获取、更改、添加或删除XML元素的标准。
HTMLDOM
HTML DOM是:
HTML的标准对象模型
HTML的标准编程接口
W3C标准
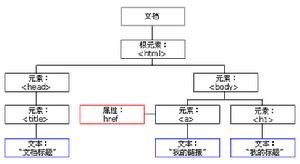
HTML DOM定义了所有HTML元素的对象和属性,以及访问它们的方法。
换言之,HTML DOM是关于如何获取、修改、添加或删除HTML元素的标准。
发展过程
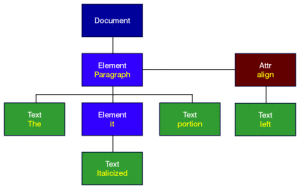
从DOM Level 1开始,DOM API 包含了一些接口,用于表示可从 XML 文档中找到的所有不同类型的信息。它还包含使用这些对象所必需的方法和属性。
Level 1包括对XML 1.0和HTML 的支持,每个 HTML 元素被表示为一个接口。它包括用于添加、编辑、移动和读取节点中包含的信息的方法,等等。然而,它没有包括对 XML 名称空间(XML Namespace)的支持,XML 名称空间提供分割文档中的信息的能力。DOM Level 2添加了名称空间支持。Level 2扩展了 Level 1,允许开发人员检测和使用可能适用于某个节点的名称空间信息。Level 2还增加了几个新的模块,以支持级联样式表、事件和增强的树操作。当前正处于定稿阶段的 DOM Level 3包括对创建 Document 对象(以前的版本将这个任务留给实现,使得创建通用应用程序很困难)的更好支持、增强的名称空间支持,以及用来处理文档加载和保存、验证以及 XPath 的新模块;XPath 是在XSL 转换(XSL Transformation)以及其他 XML 技术中用来选择节点的手段。DOM 的模块化意味着作为开发人员,您必须知道自己希望使用的特性是否受正在使用的 DOM 实现所支持。
可用特性
 DOM
DOMDOM 推荐标准的模块性质允许实现者挑选将要包括到产品中的部分,因而在使用某个特定的特性之前,首先确定该特性是否可用可能是必要的。使用 DOM Level 2 Core API,不过在着手您自己的项目时,了解如何能够检测特性是有所帮助的。
DOM 中定义的接口之一就是 DOMImplementation。通过使用 hasFeature() 方法,可以确定某个特定的特性是否受支持。DOM Level 2 中不存在创建DOMImplementation 的标准方法,不过下面的代码将展示如何使用 hasFeature() 来确定 DOM Level 2 样式表模块在某个 Java 应用程序中是否受支持。
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.DOMImplementation;
public class ShowDomImpl {
public static void main (String args) {
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder docb = dbf.newDocumentBuilder();
DOMImplementation domImpl = docb.getDOMImplementation();
if (domImpl.hasFeature("StyleSheets", "2.0")) {
System.out.println("Style Sheets are supported.");
} else {
System.out.println("Style Sheets are not supported.");
}
} catch (Exception e) {}
}
}
(DOM Level 3 将包括用于创建 DOMImplementation 的标准方法。)将使用单个文档来展示 DOM Level 2 Core API 的对象和方法。
数字正射影像图
数字正射影像图(DOM,DigitalOrthophotoMap):是对航空(或航天)像片进行数字微分纠正和镶嵌,按一定图幅范围裁剪生成的数字正射影像集。它是同时具有地图几何精度和影像特征的图像。
DOM具有精度高、信息丰富、直观逼真、获取快捷等优点,可作为地图分析背景控制信息,也可从中提取自然资源和社会经济发展的历史信息或最新信息,为防治灾害和公共设施建设规划等应用提供可靠依据;还可从中提取和派生新的信息,实现地图的修测更新。评价其它数据的精度、现实性和完整性都很优良。合肥市数字正射影像图DOM.jpg。
该图的技术特征为:数字正射影像,地图分幅、投影、精度、坐标系统、与同比例尺地形图一致,图像分辨率为输入大于400dpi;输出大于250dpi。由于DOM是数字的,在计算机上可局部开发放大,具有良好的判读性能与量测性能和管理性能等,如用农村土地发证,指认宗界地界比并数字化其点位坐标、土地利用调查等等。DOM可作为独立的背景层与地名注名,图廓线公里格、公里格网及其它要素层复合,制作各种专题图。
生产技术
制作的主要技术方法:采用航空像片或高分辨率卫星遥感图像数据等。利用:1)VintuoZo系统数字摄影测量工作站。VintuoZo系统可以利用对DEM的检测及编辑,来提高DOM的精度。还可以通过像片间、图幅间进行灰度接边,以保证影像色调的一致性。2)采用jx-4DPW系统。jx-4DPW是一套基于WINDOWSNT的数字摄影测量系统。因其对DEM的编辑采用的是单点编辑,而且该系统还具有对DOM的零立体检查的功能,故其DOM的精度较高。基于DEM的单片数字微分纠正VintuoZo系统具有单片数字微分纠正的模块。
数字正射影像图的应用
洪水监测、河流变迁、旱情监测;
农业估产(精准农业);
土地覆盖与土地利用土地资源的动态监测;
荒漠化监测与森林监测(成林害虫);
海岸线保护;
生态变化监测。
DOM的优势主要表现在:易用性强,使用DOM时,将把所有的XML文档信息都存于内存中,并且遍历简单,支持XPath,增强了易用性。
DOM的缺点主要表现在:效率低,解析速度慢,内存占用量过高,对于大文件来说几乎不可能使用。另外效率低还表现在大量的消耗时间,因为使用DOM进行解析时,将为文档的每个element、attribute、processing-instrUCtion和comment都创建一个对象,这样在DOM机制中所运用的大量对象的创建和销毁无疑会影响其效率。
访问节点
DOM你可通过若干种方法来查找您希望操作的元素:
通过使用getElementById()和getElementsByTagName()方法
通过使用一个元素节点的parentNode、firstChild以及lastChild 属性
getElementById()和getElementsByTagName()这两种方法,可查找整个HTML文档中的任何HTML元素。
这两种方法会忽略文档的结构。假如您希望查找文档中所有的<p>元素,getElementsByTagName()会把它们全部找到,不管<p>元素处于文档中的哪个层次。同时,getElementById()方法也会返回正确的元素,不论它被隐藏在文档结构中的什么位置。
这两种方法会向您提供任何你所需要的HTML元素,不论它们在文档中所处的位置!
getElementById()可通过指定的ID来返回元素:
getElementById()语法
document.getElementById("ID");注释:getElementById()无法工作在XML中。在XML文档中,您必须通过拥有类型id的属性来进行搜索,而此类型必须在XML DTD中进行声明。
getElementsByTagName()方法会使用指定的标签名返回所有的元素(作为一个节点列表),这些元素是您在使用此方法时所处的元素的后代。
getElementsByTagName()可被用于任何的 HTML 元素:
getElementsByTagName()语法
document.getElementsByTagName("标签名称");或者:
document.getElementById('ID').getElementsByTagName("标签名称");
实例1
下面这个例子会返回文档中所有<p>元素的一个节点列表:
document.getElementsByTagName("p");
实例2
下面这个例子会返回所有<p>元素的一个节点列表,且这些<p>元素必须是id为"maindiv"的元素的后代:
document.getElementById('maindiv').getElementsByTagName("p");
节点列表
当我们使用节点列表时,通常要把此列表保存在一个变量中,就像这样:
var x=document.getElementsByTagName("p");现在,变量x包含着页面中所有<p>元素的一个列表,并且我们可以通过它们的索引号来访问这些<p>元素。
注释:索引号从0开始。
您可以通过使用length属性来循环遍历节点列表:
var x=document.getElementsByTagName("p");for(var i=0;i<x.length;i++){// do something with each paragraph}您也可以通过索引号来访问某个具体的元素。
要访问第三个<p>元素,您可以这么写:
var y=x;
parentNode、firstChild以及lastChild
这三个属性 parentNode、firstChild以及lastChild可遵循文档的结构,在文档中进行“短距离的旅行”。
请看下面这个HTML片段:
<table>
<tr>
<td>John</td>
<td>Doe</td>
<td>Alaska</td>
</tr>
</table>
在上面的HTML代码中,第一个<td>是<tr>元素的首个子元素(firstChild),而最后一个<td>是<tr>元素的最后一个子元素(lastChild)。
此外,<tr>是每个<td>元素的父节点(parentNode)。
对 firstChild 最普遍的用法是访问某个元素的文本:
var x=; var text=x.firstChild.nodeValue;parentNode属性常被用来改变文档的结构。假设您希望从文档中删除带有id为"maindiv"的节点:
var x=document.getElementById("maindiv"); x.parentNode.removeChild(x);首先,您需要找到带有指定id的节点,然后移至其父节点并执行removeChild()方法。
优点和缺点
DOM的优势主要表现在:易用性强,使用DOM时,将把所有的XML文档信息都存于内存中,并且遍历简单,支持XPath,增强了易用性。
DOM的缺点主要表现在:效率低,解析速度慢,内存占用量过高,对于大文件来说几乎不可能使用。另外效率低还表现在大量的消耗时间,因为使用DOM进行解析时,将为文档的每个element、attribute、processing-instrUCtion和comment都创建一个对象,这样在DOM机制中所运用的大量对象的创建和销毁无疑会影响其效率。
参考资料
1.基于DOM模型扩展的Web信息提取·知网
2.XML文档对象模型持久化在OSCAR中的实现及查询转换 ·知网
")
")
")
")